
In many HR departments, rewriting reports to hide personal data remains a common practice for data protection purposes. Titles, initials, locations, or any clue that could identify a person are manually modified before sharing the document. This “artisanal” solution is perceived as fast, controllable, and above all, safe.
However, recent research and regulatory bodies agree that this practice is not only insufficient—it can result in GDPR violations, lost time, and poorly informed decisions. According to a Gartner report, HR managers spend between 10% and 20% of their weekly time manually preparing reports, representing an invisible but real cost to many organizations.
This article debunks the myths of this practice, analyzes real-world data breaches, and explores what the GDPR demands and how to address it with automated solutions.
What types of personal data are managed in HR, and how are they rewritten?
HR departments handle a wide range of sensitive personal data, including:
- Name, address, and contact details
- Personal identifiers like national IDs or employee numbers
- Medical or psychological information
- Performance data, evaluations, and sanctions
- Data on gender, age, ethnicity, or family status

When this data is manually rewritten to protect privacy, generic labels are often used like “Employee X,” “Senior Manager,” or “Logistics Department.” However, these substitutions don’t always prevent identification, especially when combined with role, context, and employment history.
This approach is flawed because it introduces subjectivity and does not ensure true anonymization. It also fails to measure reidentification risk or generate technical evidence that a secure process was applied.
Real-World cases that demonstrate the risk
- Post Office, UK (2024): Accidentally published names and addresses of Horizon scandal victims due to poorly redacted documents.
- Mueller Report, USA (2019): Digital redaction errors exposed sensitive information.
- Lloyds Banking Group, UK (2025): Manual review failure allowed a client to see confidential data of others.
- ICO, UK: Poor redaction in adoption documents enabled biological parents to identify adoptive ones.
- Meta, USA (2025): Redaction errors exposed confidential data during legal dispute with Apple and Google.
The false sense of security
The first major flaw in manual rewriting is its subjectivity. What one reviewer considers “de-identified” may still be identifiable. Attributes like department, age, gender, location, and job level can easily combine to enable reidentification.
A study by researcher Latanya Sweeney showed that 87% of U.S. citizens could be identified using only birth date, ZIP code, and gender. This issue isn’t exclusive to the U.S.—European companies modifying reports with internal, non-technical criteria face the same risks.
Moreover, in an audit scenario, HR or Compliance teams cannot provide technical evidence that data was protected according to GDPR standards. Traceability, repeatability, and documentation are key to demonstrating compliance.
What does international data protection law require?
- GDPR (EU): Requires data protection by design and default, data minimization, pseudonymization or anonymization when possible, and process traceability (Articles 5, 25, and 32).
- HIPAA (USA): Enforces confidentiality, integrity, and availability of medical information, including proper de-identification.
- CCPA (California, USA): Grants privacy rights and demands that personal data is not misused, sold, or reidentified.
- AI Act (EU): Requires AI systems processing personal data to include robust privacy and auditability mechanisms.
What should HR departments do?
Departments must:
- Apply effective and documented anonymization techniques.
- Ensure full traceability of data processing.
- Avoid relying on manual practices without validation.
- Ensure not only legal but also ethical handling of human data.
What alternatives exist?
To address these challenges, more organizations are implementing contextual automated anonymization, a method that adjusts the level of protection to the usage context while preserving the document’s semantics and structure. This enables analysis without reidentification, ensuring both utility and privacy.
Unlike pseudonymization, which is reversible with a key, contextual anonymization makes reidentification impossible while preserving analytical value. It also creates full traceability, audit logs, and risk metrics—key components to meet GDPR and global regulatory standards.
Why is it worth making the change?
How Nymiz optimizes the protection of sensitive data in reports
Nymiz provides an advanced and specialized solution to ensure data protection in human resources without sacrificing operational efficiency or analytical quality. Our technology responds to today’s challenges with automated, auditable mechanisms aligned with GDPR, HIPAA, CCPA, and the AI Act.
Key benefit of Nymiz for privacy protection
Nymiz’s approach is based on adaptive contextual anonymization, which replaces sensitive data without altering document structure or semantics. This ensures reports remain useful for HR analysis—climate, diversity, performance—without compromising individual identities.
Each anonymization instance generates risk metrics, technical logs, and documentary evidence, allowing organizations to demonstrate compliance in audits or regulatory reviews.
Nymiz features that address these challenges
To address the diverse privacy and compliance requirements of organizations’ HR environments, Nymiz offers a comprehensive set of features designed to ensure the complete protection of sensitive data without compromising the analytical value, structure, or context of the information:
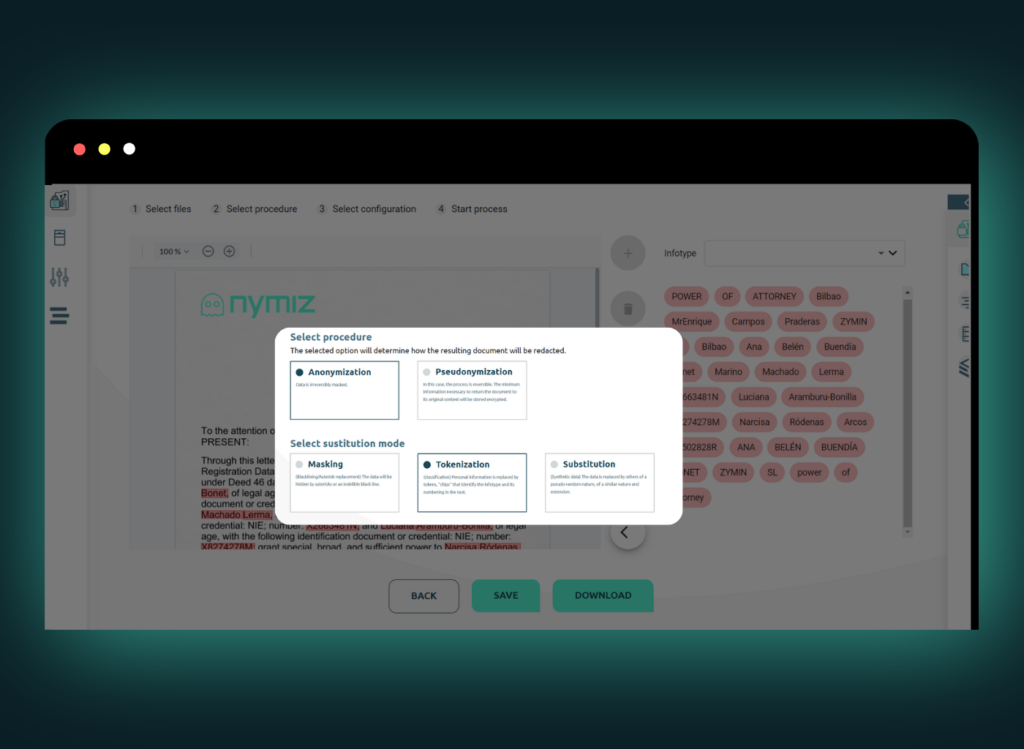
- Document anonymization: Automatically removes or transforms identifiable information in structured and unstructured HR reports, preserving their formatting. This ensures regulatory compliance without affecting usability.
- Plain text anonymization: Processes open-text inputs, such as employee comments, internal communications, or emails. This enables privacy protection even for open-source and unstructured content.
- Manual review oversight: Enables human verification in the loop when necessary, combining automation with oversight to ensure contextual accuracy.
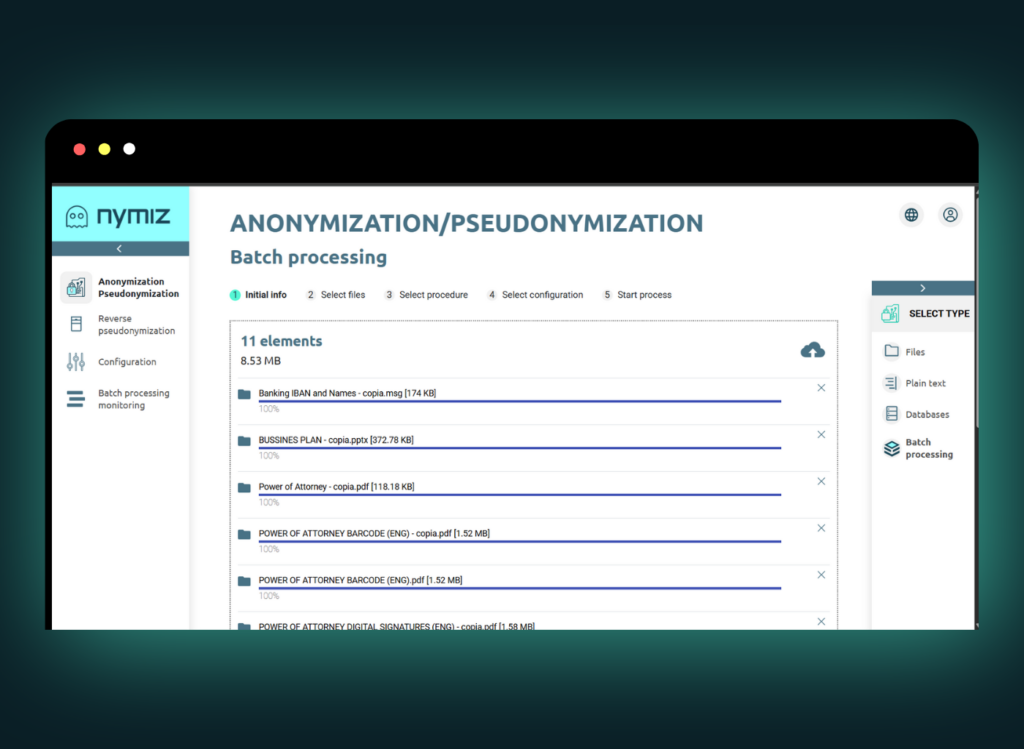
- Batch processing: Anonymizes large volumes of documents or records simultaneously, saving time and ensuring consistent application of privacy standards.
- Database anonymization: Applies contextual anonymization directly to HR databases, enabling secure data access for analysis without exposing sensitive fields.
These capabilities ensure that sensitive data is protected in different formats, orientations, and workflows, without sacrificing analytical value, document structure, or contextual understanding.
These features eliminate reliance on manual processes and enable scalable, consistent, and secure operations.
How Nymiz supports AI integration in HR departments
Nymiz not only protects data from internal and regulatory risks, but also prepares HR teams for environments where AI is part of decision-making. Our solution ensures that data used by AI models is anonymized from the source, avoiding bias and protecting privacy in analytics, classification, or prediction systems.
With API integrations and a modular architecture, Nymiz fits seamlessly into existing HR platforms, BI tools, or AI ecosystems—enabling safe, responsible analytics aligned with new regulations.
Conclusion
Protecting sensitive information in human resources isn’t about improvisation. The GDPR and other data protection laws demand demonstrable, auditable mechanisms. Manual rewriting is not a valid strategy—it’s a risky shortcut that can compromise individuals and organizations alike.
Fortunately, alternatives exist. Tools like Nymiz allow HR teams to automatically anonymize large volumes of information, without losing accuracy or time, and with all the technical evidence required by regulators.
Want to see how this works in your organization? Request a demo at Nymiz.







