
The integration of artificial intelligence (AI) in biomedicine has opened new opportunities in diagnostics, personalized medicine, and genetic research. AlphaGenome, DeepMind‘s model, marks a milestone in this evolution by promising to revolutionize the interpretation of the human genome. However, this advancement has reignited an urgent debate, especially following recent cases such as the 23andMe data breach or misuse reports involving genealogy platforms like MyHeritage: are the genetic data used in these developments sufficiently protected?
This article explores the AlphaGenome case to reflect on the risks posed by the use of biomedical data in AI systems, even when such data is de-identified. It also delves into the value and sensitivity of this data, the applicable regulatory framework, and technological solutions that allow for a balance between innovation and privacy in the context of genetic data protection in artificial intelligence.
What are genetic data?
Genetic data is a type of highly sensitive personal information that contains details about an individual’s biological composition. It is obtained through the analysis of DNA and RNA, allowing the identification of hereditary traits, disease predispositions, physical characteristics, or even ancestry. This data is not only unique to each person but also has implications for biological relatives, making it a particularly protected category under privacy regulations.

Its value for biomedical research, personalized medicine, and the development of artificial intelligence (AI) models is undeniable. However, this potential also brings significant risks if not managed properly: from re-identification to misuse for commercial or discriminatory purposes. Therefore, genetic data protection in artificial intelligence is an urgent and essential challenge.
The sensitivity of genetic data has led both the General Data Protection Regulation (GDPR) in Europe and other international regulations to classify it as special category data, requiring enhanced security measures and additional ethical safeguards for its processing.
Why do genetic data require enhance protection?
Unlike other personal data, genetic data is permanent, immutable, and highly identifiable. It not only reveals information about the individual to whom it belongs but also about their biological relatives, extending its reach beyond the original data subject.
Moreover, its value for research and personalized medicine makes it an attractive target for third parties: from insurers to employers or tech platforms. For this reason, the General Data Protection Regulation (GDPR) includes it in Article 9 as “special categories of data”, meaning it can only be processed under very specific conditions, such as explicit consent or public interest in the healthcare field.
In AI contexts, where this data is used to train models for diagnosis, disease prediction, or drug development, it is essential to ensure that processing complies with principles such as:
- Data minimization: processing only what is strictly necessary.
- Anonymization or prior pseudonymization: to avoid re-identification.
- Transparency: about data use and processing purposes.
- Access limitation: controlling which entities or systems interact with the data.
Ensuring these principles is not only a legal requirement but also an ethical one, especially when dealing with data that touches the deepest identity of a person. All of this reinforces the importance of rigorously and responsibly addressing genetic data protection in artificial intelligence.
Special category data: Definition and examples
Genetic data is considered special category data under Article 9 of the GDPR. This includes:
- DNA or RNA information.
- Data derived from genetic analyses (exome, whole genome).
- Hereditary information that may infer diseases, physical or psychological traits.
In the context of biomedical AI, protecting this data becomes critical not only because of the associated risks but also because of the need to ensure the ethical and legal use of information. This is where genetic data protection in artificial intelligence becomes a technical and regulatory priority.
What is AlphaGenome and why is it relevant?
AlphaGenome is an artificial intelligence system developed by DeepMind (Google) with the ambitious goal of deciphering the functions of all genes in human DNA. Based on deep learning models similar to AlphaFold, AlphaGenome accurately analyzes genetic variants and predicts their functional impact, potentially revolutionizing personalized medicine.
This model was introduced in 2024 and aims to create a “manual of instructions” for the genome, capable of shedding light on the 98.5% of human DNA still not understood. Its development builds on the Human Genome Project database, expanding its predictive capabilities with data obtained from diverse global populations. This enables improved diagnosis of rare diseases, prediction of drug responses, and design of more effective therapies.

However, its operation relies on the availability of large volumes of highly sensitive genetic data. This raises serious privacy challenges, as even with de-identification, re-identification is possible. For example, in the well-known ChestX-ray14 dataset study, patients were re-identified with 95.55% accuracy using AI. Such cases demonstrate that genetic and biomedical patterns can be traced back to specific individuals, highlighting that traditional de-identification techniques are not always sufficient when it comes to genetic data protection in artificial intelligence. The AlphaGenome case thus becomes a paradigmatic example of the balance that must exist between scientific innovation and genetic data protection in artificial intelligence.
Genetic data: A powerful and vulnerable asset
Genetic data contains unique, permanent, and irreversible information about individuals, enabling the identification of hereditary traits, disease predispositions, and the construction of detailed health profiles. Their sensitivity is amplified by also involving biological relatives, which justifies their classification as special category data under the GDPR.

What privacy risks do these data face?
When used to train AI models without adequate safeguards, this data can be exposed to serious threats such as:
- Re-identification: Even after removing names, genetic patterns can be traced back to specific individuals.
- Genetic discrimination: Companies could use this information to deny insurance coverage or employment.
- Unauthorized use: Cross-referencing with other sources may reveal sensitive, non-consensual information.
These risks demand robust safeguards for genetic data protection in artificial intelligence, particularly in advanced research settings.
Real challenges: The MyHeritage case
A relevant example occurred in 2021, when the Spanish consumer organization OCU filed a complaint against MyHeritage for sharing genetic data without consent. The Spanish Data Protection Agency (AEPD) found violations of Articles 6, 7, and 13 of the GDPR, related to lawfulness, explicit consent, and information to the data subject, respectively. The company was fined €20,000 and required to reform its data processing practices across several countries.
This case revealed a lack of transparency and a disregard for users’ rights, highlighting the critical need to ensure genetic data protection in artificial intelligence from the design stage of any biomedical system or platform.
Case study: 23andMe, massive genetic data breach
This case illustrates the consequences of poor privacy management. In 2023, the 23andMe lab confirmed a data breach that affected nearly 7 million users. Attackers accessed highly sensitive data such as genetic ancestry, family matches, and locations. Although the data were de-identified as per regulations, cross-referencing with other databases allowed for the reconstruction of personal profiles, re-identifying individuals.
The breach originated through credential stuffing techniques, exploiting passwords leaked from other platforms. This not only severely damaged 23andMe’s reputation but also jeopardized public trust in the use of biomedical data for scientific purposes.
In response, the Spanish Data Protection Agency (AEPD) launched an investigation. Although 23andMe is based in the U.S., it is required to comply with the GDPR when handling data of European citizens. This case underscores the need for robust genetic data protection in artificial intelligence, even beyond European borders.
What does the law say about genetic data protection in AI?
The protection of biomedical data is primarily governed by three European regulations:
- GDPR (General Data Protection Regulation): Articles 9 and 35 establish enhanced protection for sensitive data and the obligation to conduct Data Protection Impact Assessments (DPIAs) for high-risk processing.
- AI Act (Artificial Intelligence Regulation): Classifies as high-risk those AI systems using sensitive data, requiring a Fundamental Rights Impact Assessment (FRIA).
- Biomedical Research Law (Spain): Requires informed consent for the use of biological samples and genetic data for research purposes.
Sanctions for Non-Compliance
Although all these laws address sensitive data protection, each provides different penalties for non-compliance:
- GDPR: Up to €20 million or 4% of global annual turnover.
- AI Act: Up to €30 million or 6% of global turnover for training AI with sensitive data without adequate safeguards.
- AEPD (Spain): Applies proportional fines, administrative sanctions, and corrective measures based on the severity of the breach.
Cases like 23andMe demonstrate that these regulations also apply to non-EU companies when handling the data of EU citizens, reinforcing the global dimension of genetic data protection in artificial intelligence.
Technological solutions that protect without hindering innovation
- Advanced anonymization: An irreversible technique that transforms data to remove any personal identifiers, ensuring that data cannot be traced or re-identified, even when shared with AI models.
- Tokenization: Replaces sensitive data with tokens that maintain the original data structure, preserving its utility without revealing its actual content.
- Synthetic data: Generates artificial datasets that replicate real-world patterns without corresponding to specific individuals, enabling model training without compromising privacy.
These solutions not only strengthen data security but also foster collaboration between hospitals, laboratories, and research centers, facilitating large-scale projects without compromising individual privacy.
Use cases for these solutions
- Advanced anonymization: The Broad Institute has led international collaborative projects using anonymized genetic data, enabling population studies without re-identification risk.
- Tokenization: Hospitals like Mount Sinai in the U.S. have begun implementing tokenization to protect patient identifiers in AI systems.
- Synthetic data: Platforms such as Syntegra and Synthea have shown that synthetic data can train reliable predictive models in real-world healthcare environments.
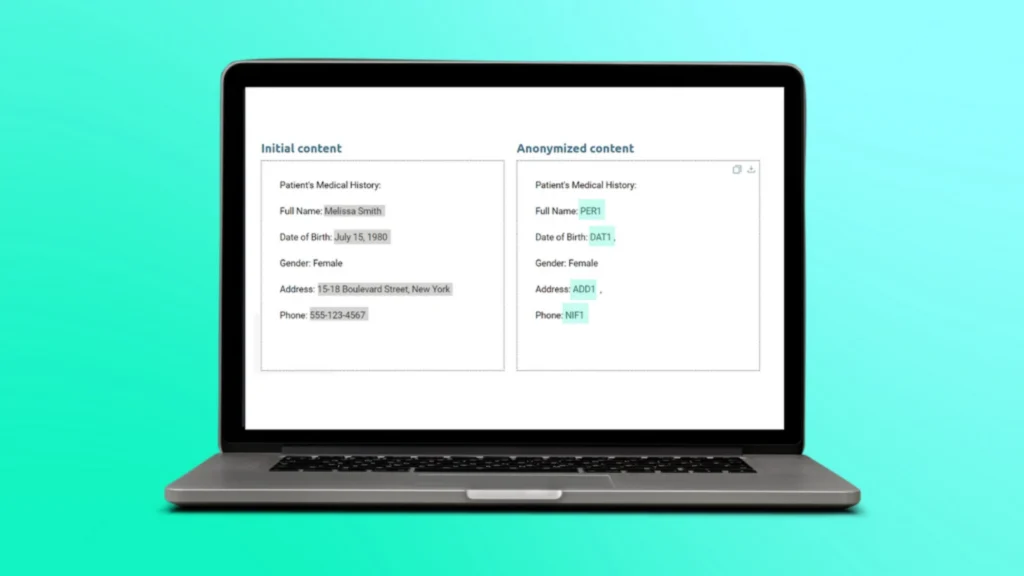
How Nymiz helps protect biomedical data
Nymiz offers advanced intelligent anonymization solutions specifically designed for biomedical settings. Its platform automates anonymization processes in compliance with GDPR and the AI Act, adapting each configuration to the characteristics of genetic data.
Moreover, it preserves the analytical value of anonymized data, facilitating its use in research without sacrificing privacy. It also includes key functionalities such as data traceability, compliance evidence, and access control, essential for biobanks and hospitals.
With these capabilities, Nymiz positions itself as a strategic ally for implementing ethical and secure AI in healthcare.
Towards an ethic of innovation in biomedicine
AlphaGenome marks a turning point in AI-driven biomedicine. But it also highlights the privacy risks associated with using sensitive genetic data. If we want to move toward more precise and personalized medicine without compromising fundamental rights, we must apply strong genetic data protection in artificial intelligence measures from the outset.
The path to responsible innovation requires ensuring data traceability, implementing effective anonymization solutions, and fostering an organizational culture based on ethics and transparency. Only in this way can AI transform health without eroding patient trust.
Discover ethical and responsible innovation with Nymiz
Nymiz offers intelligent anonymization solutions to protect biomedical data without sacrificing its analytical value. It automates GDPR and AI Act compliance with 95% accuracy, reducing manual processing time by 80% while preserving the analytical value of genetic data. Book your personalized demo and discover how to protect privacy and lead ethical biomedical innovation.








