Currently, we live in a society where privacy and personal data management coexist. The widespread use of the internet in activities such as online shopping, email usage, and data storage in software programs has led to cybercrime focusing on the theft of personal data.
Traditional crime has evolved, just like new technologies, into cybercrime. It is increasingly common to see companies from all sectors being hacked with the aim of stealing the personal data they have stored. As a result, organizations have been compelled to face the challenge of managing and protecting personal data.
Among the strategies and techniques to protect data, data masking provides an extra layer of security to the storage of personal data. This method solves the challenge for companies to protect the privacy of data, rendering it irrelevant to cybercriminals.
WHAT IS DATA MASKING IN UNSTRUCTURED FILES?
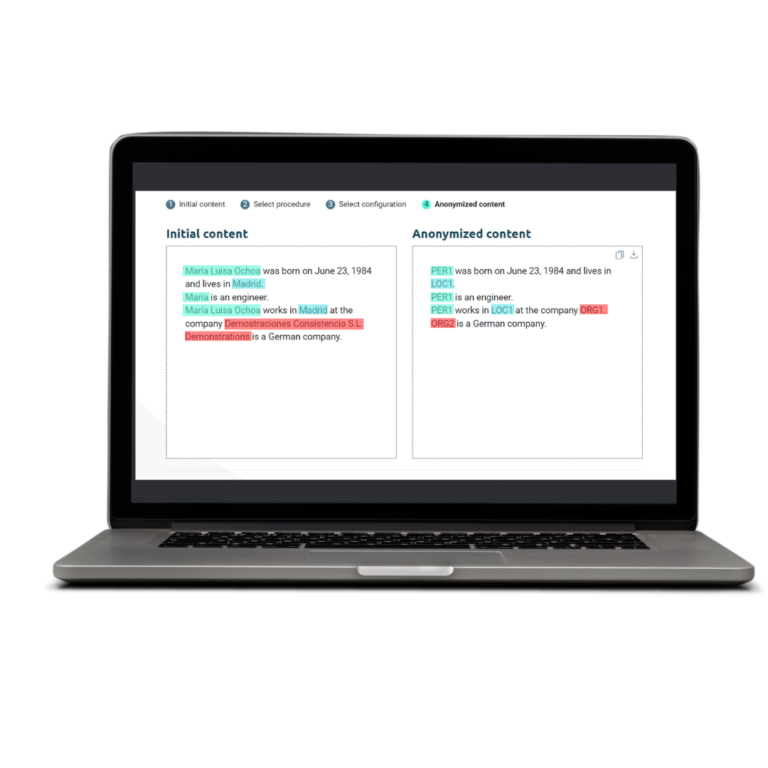
Data masking is a technique that involves the hiding or modification of sensitive personal data in unstructured files such as emails, text files, PDFs, video, and audio. The goal is for this data to be deleted or made unrecognizable to those without authorized access. This technique safeguards the privacy of personal data and the confidentiality of information to be shared or used, preventing these files from being maliciously used or falling into the wrong hands.
Thanks to this technique, it is possible to preserve the integrity and coherence of information in documents, maintaining their structure and basic characteristics so they remain useful for intended purposes. In other words, even though the data has been protected, unstructured files remain valid for use in testing, analysis, software development, and other processes, without exposing the personal data of the individuals involved.
In essence, data masking in unstructured documents simplifies the challenge of protecting data in documents while maintaining their usefulness for use, sharing, and distribution. In this regard, there are different data masking methods that can be adapted to the intended use of the documents.
For example, in cases where it is necessary to maintain document readability, the substitution with synthetic data or tokens is applied. In cases where the sole objective is to protect or eliminate data without the need to maintain context or readability, deletion is generally applied. The following section details the various available methods and the benefits they offer.
TYPES AND EXAMPLES OF DATA MASKING IN UNSTRUCTURED FILES
There are different data masking techniques, each with its own advantages and disadvantages depending on the context in which they are used.
Deletion
Equivalent to blacklining/asterisk. Useful when the only goal is to eliminate data and there is no need to maintain readability or integrity. The documents will not be used for analytics, research, or knowledge management. The sole purpose is protection.
Substitution (with synthetic data)
Useful for cases where readability and context need to be maintained. When advanced analytics need to be applied later, maintaining the format and nature of the data is essential; this method is ideal for such cases. For instance, if we want to use GPT chat without exposing real personal data, this data masking method can be applied to maintain context and coherence and then use the tool.
Tokenization (substitution with tokens)
Useful for cases where context, readability, and traceability need to be maintained. However, synthetic data is not desired to avoid potential confusion; hence, tokens are used instead of synthetic data. Moreover, tokens can be customized. This is highly useful for turning documents into reusable templates and contributing to document management automation.
USE CASES WHERE DATA MASKING IN UNSTRUCTURED FILES IS CRUCIAL
Data masking in unstructured files is employed in various situations to protect the privacy and confidentiality of sensitive information. Here are some use cases where data masking methods are used:
Protecting data in HR departments: HR departments store and manage personal data in unstructured files such as emails, resumes, employee records, and more. Data masking in unstructured files eliminates and replaces sensitive personal data like names, addresses, phone numbers, license plates, to protect files from security breaches and comply with GDPR retention deadlines.
Legal sector: Legal knowledge management involves sharing legally relevant documents among all members of law firms or legal areas. However, to make document sharing possible, personal data of parties needs to be masked to comply with GDPR. In these cases, maintaining document readability and context is crucial, facilitating reading and understanding. This requires consistent data consistency by replacing original data with tokens or synthetic data.
Data analysis and software testing: Companies use substantial amounts of valuable information to perform performance analysis, purchasing patterns, application testing, among others, to improve business profitability. Data masking allows elimination or modification of personal data while retaining the structure and context of the information. This way, companies can conduct relevant analyses without jeopardizing the confidentiality of individuals’ personal data.
Data sharing in the healthcare sector: In research environments, healthcare organizations may need to share databases and documents (medical histories, analytics, etc.) with third parties for study purposes. To achieve this, personal patient data needs to be eliminated, ensuring GDPR compliance. Data masking eliminates this data, enabling the sharing of unstructured files without exposing sensitive and confidential information. Moreover, by replacing data with tokens, traceability of information is ensured, and patients are identified with fictional identifiers that prevent re-identification.
BENEFITS OF UNSTRUCTURED DATA MASKING
Unstructured data masking is essential for companies or organizations as it allows them to prevent data exposure in cyberattacks involving information leakage. By using data masking techniques, companies can protect their sensitive personal information from potential security breaches and misuse. Even if documents end up in the hands of unauthorized third parties, personal data will remain protected due to data masking. Consequently, the information available to attackers or unauthorized third parties becomes valueless, as the real value lies in personal data.
Furthermore, masking data does not equate to losing the value of information. Thanks to various substitution methods, it is possible to protect documents while maintaining their usefulness for sharing and usage. This sets data masking apart from other security measures that act at the level of documents, repositories, systems, etc. This is particularly important for organizations that wish to use data for research development and software testing, as masked data can still provide valuable information without compromising user privacy.
As indicated by the General Data Protection Regulation (GDPR), companies must establish techniques for the proper use of personal data they collect, use, and store. Data masking ensures that personal information is stored and used while protecting its privacy and confidentiality. Additionally, it complies with the principle of minimization of processing, limiting the time companies have to retain data in a secure and limited manner.
Another benefit of using data masking methods is limiting access to sensitive information. Data masking limits access and sharing of information with third parties, preventing it from falling into the wrong hands or being used improperly. This helps comply with GDPR regulations and prevents potential leaks from resulting in reputational and financial damage.
NYMIZ, YOUR ALLY FOR MASKING DATA IN TEXT AND PDF FILES
Unstructured personal data masking is a crucial technique to protect individuals’ privacy and ensure the security of information stored and managed in unstructured files.
Nymiz is specialized software for automating the masking of unstructured documents. Through the use of artificial intelligence, Nymiz identifies personal data in unstructured documents and subsequently applies the masking method selected by the user. Through a simple process, companies can ensure data protection in documents, saving time and effort. With Nymiz, our clients:
1. Address the challenge of protecting personal data in unstructured documents. It is estimated that around 80% of information in companies corresponds to unstructured information, making its protection a significant challenge.
2. Save time and effort by converting a manual task into an automated workflow.
3. Customize data masking in documents to protect only the necessary information for each use case: sharing, distribution, or analytics.
For this purpose, Nymiz offers automated processing of batches of documents quickly and easily. With a single click, Nymiz allows the processing of large quantities of documents quickly.
Through its AI, Nymiz identifies personal data and automatically masks it. Additionally, it includes functionalities that allow customization of results as needed for each use case: whitelist, blacklist, or manual supervision.