
La conversación sobre confianza cero suele empezar (y a veces terminar) en identidades, redes y accesos. “Never trust, always verify”. Es un avance enorme, y NIST lo define con claridad: Confianza cero se centra en proteger recursos y flujos de trabajo, no perímetros.
Pero en 2025–2026 hay un cambio silencioso: el nuevo perímetro son los datos. Porque hoy los datos viajan más que nunca: entre equipos, proveedores, clouds y, sobre todo, hacia flujos de automatización y modelos de IA. Y ahí aparece un reto habitual en adopciones de IA: puedes tener controles de acceso impecables y, aun así, exponer información sensible en el momento de uso.
Zero Trust ya no es “una tendencia”: se ha vuelto estructural. De hecho, el 73% de las organizaciones están implementando activamente estrategias Zero Trust o planean hacerlo, impulsadas sobre todo por la necesidad de proteger datos, prevenir brechas y reducir amenazas internas.
La pregunta ya no es “¿tengo confianza cero?”.
La pregunta es: ¿mis datos viven en un ecosistema de datos de confianza cero?
Confianza cero ya no es solo red e identidades: el nuevo perímetro son tus datos
En entornos híbridos, con colaboración interna y externa, y con IA cada vez más presente en procesos críticos, el dato se ha convertido en el activo más móvil… y también en el más expuesto. A diferencia de otros momentos, la innovación no depende solo de acceso, sino de reutilización continua del dato: para análisis, automatización, reporting, auditorías o entrenamiento y evaluación de modelos.
Esto explica por qué muchas organizaciones se sienten seguras “en teoría” y vulnerables “en la práctica”: la protección se concentra en perímetro y acceso, mientras que el riesgo real aparece cuando el dato sale de su contexto original y empieza a circular.
El límite del Zero Trust “tradicional”: protegido en reposo y tránsito… expuesto en uso
El cifrado, la segmentación y el control de acceso protegen datos en reposo y en tránsito, pero cuando un usuario (o un sistema) accede legítimamente a un documento o dataset, ese contenido puede:
- replicarse en múltiples herramientas,
- compartirse con terceros,
- entrar en pipelines de IA,
- o quedar expuesto por errores operativos, especialmente cuando los datos se reutilizan en múltiples sistemas y flujos.
En otras palabras: la seguridad perimetral y de acceso es necesaria, pero no suficiente. Si tu organización está desplegando IA, necesitas un principio operativo: no confiar en el dato sin protección, incluso dentro de casa.
Qué es un ecosistema de datos de confianza cero
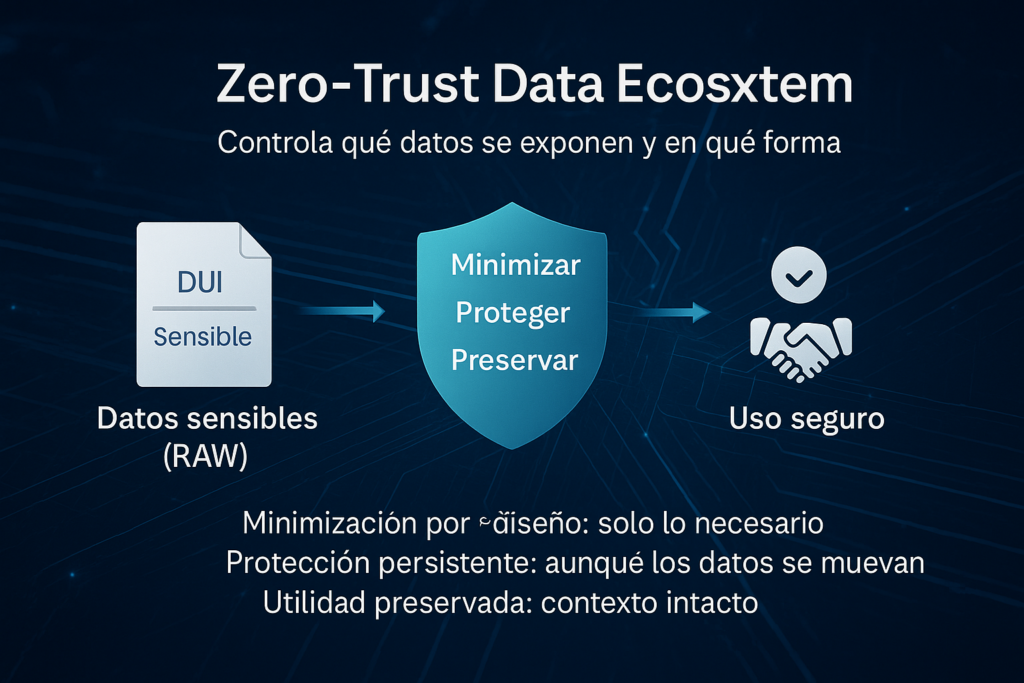
Un zero-trust data ecosystem es una forma de operar donde los datos sensibles no circulan “tal cual” por defecto. En lugar de basarse únicamente en “quién accede”, se basa en “qué datos se exponen” y “en qué forma”, aplicando protección sistemática para reducir el riesgo incluso cuando el dato se mueve.
En la práctica, esto implica tres cambios:
- Minimización por diseño: compartes solo lo necesario.
2. Protección persistente: el dato sigue protegido aunque cambie de sistema, equipo o proveedor.
3. Utilidad preservada: la información sigue siendo válida para IA, analítica y operaciones, sin “romper” el contexto.
Este enfoque encaja con la evolución del propio Zero Trust: las organizaciones no solo buscan “controlar accesos”, sino reducir probabilidad de brecha, impacto operativo y riesgo interno. Por eso, extender esos principios al dato, y no solo al acceso, es el paso natural hacia un ecosistema de datos de confianza cero.
Por qué la anonimización avanzada es el acelerador (y no un freno)
Existe una idea equivocada: que proteger datos siempre reduce valor. Eso ocurre cuando la protección se hace de forma manual, inconsistente o excesiva. La anonimización avanzada cambia el juego porque busca un equilibrio difícil pero crítico: reducir la identificabilidad sin destruir contexto.
En un ecosistema de datos de confianza cero, la anonimización avanzada es un acelerador por tres motivos:
- Reduce exposición de forma sistemática (no puntual).
- Hace escalable la colaboración y el uso de IA sin fricción manual.
- Mantiene la utilidad del dato para automatización, investigación, auditoría y modelos.
Y lo más relevante: Zero Trust no solo reduce riesgo, también puede generar retorno medible. Microsoft reportó un 92% de ROI en tres años, con payback en menos de seis meses, y una reducción del 50% en la probabilidad de brecha al adoptar disciplinas de Zero Trust. De forma similar, Zscaler observó $4.1M en ahorros, 139% de ROI y 85% menos ataques de ransomware exitosos con su modelo Zero Trust Exchange.
Si esos resultados aparecen al reforzar controles y disciplina Zero Trust, el siguiente salto lógico es proteger el activo más crítico: los datos. Ahí es donde la anonimización avanzada acelera la adopción de IA dentro de un ecosistema de datos de confianza cero, porque reduce exposición sin destruir utilidad.
Cómo Nymiz ayuda a construir un ecosistema de datos de confianza cero con anonimización avanzada
En Nymiz diseñamos nuestra tecnología para que la protección del dato no sea un paso manual “al final”, sino una capa integrada en los flujos de trabajo. Ese enfoque es clave para un ecosistema de datos de confianza cero: los datos sensibles se transforman de forma consistente, gobernada y escalable antes de circular por la organización o entrar en procesos de IA.
¿Qué habilita esto en la práctica?
- Anonimización avanzada en documentos no estructurados (PDFs, contratos, expedientes, emails exportados, presentaciones), preservando estructura y legibilidad para que el contenido siga siendo útil.
- Seudonimización consistente para mantener trazabilidad controlada cuando el caso de uso lo requiere (auditoría, análisis, workflows legales).
- Configuraciones por proyecto (reglas, excepciones e infotipos) para alinear la protección con políticas internas y requisitos normativos, evitando enfoques “one size fits all”.
- Procesamiento por lotes para aplicar las mismas reglas a gran volumen, reduciendo riesgo operativo y dependencia de tareas manuales.
- Supervisión y validación cuando se necesita un control adicional de calidad.
Y el resultado es tangible: los equipos pueden anonimizar en segundos, con más de un 95% de precisión en textos complejos y ahorrar hasta un 80% del tiempo frente a métodos manuales o tradicionales, sin renunciar al valor del dato ni romper el contexto que la IA necesita para funcionar.
En 2026, la ventaja no será “usar IA”, sino hacerlo con privacidad como infraestructura: rápida, consistente y lista para escalar dentro de un ecosistema de datos de confianza cero.
Técnicas clave: no todo se protege igual (y eso es buena noticia)
Un ecosistema de datos de confianza cero no se construye con una única técnica. Se construye con un enfoque gobernado que elige el método según el caso de uso, el nivel de riesgo y la necesidad de trazabilidad.
Seudonimización: privacidad con trazabilidad controlada
Ideal cuando necesitas consistencia (misma entidad, mismo pseudónimo) para preservar coherencia en procesos legales, auditorías, análisis o automatizaciones.
Enmascaramiento y generalización: minimización práctica
Útil cuando solo necesitas rangos o categorías (p.ej., edad aproximada, región, segmento), reduciendo exposición sin perder utilidad operativa.
Datos sintéticos y enfoques robustos: cuando el riesgo es alto y el uso es intensivo
Cuando necesitas entrenar, evaluar o testear modelos sin datos reales, los datos sintéticos pueden habilitar innovación con menor exposición (siempre con controles de calidad y evaluación de riesgo).
Privacidad diferencial: protección estadística en escenarios de agregación
Adecuada cuando se trabaja con analítica y se quiere limitar la reidentificación a partir de consultas repetidas sobre datos agregados.
El marco práctico: 5 pasos para construir tu ecosistema de datos de confianza cero
Si quieres construir un ecosistema de datos de confianza cero de forma realista (especialmente en sector público, banca, legal o salud), este marco funciona porque combina descubrimiento de datos, automatización y gobernanza.
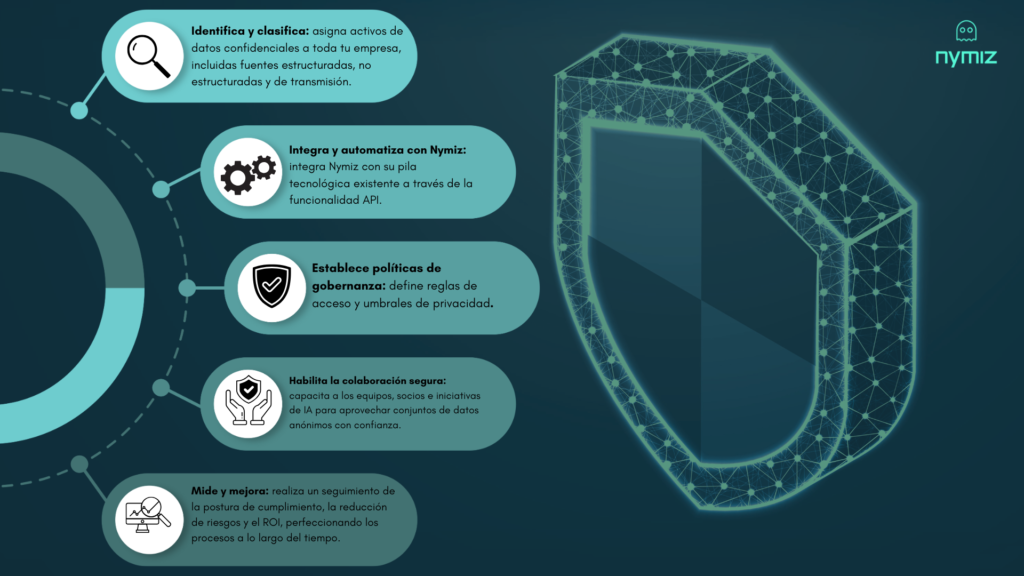
1)Identificar y clasificar: inventario real (incluyendo no estructurado)
Empieza por mapear qué tipos de documentos/datasets manejas, dónde viven, qué contienen (PII, datos sensibles) y qué flujos los consumen (incluida IA). Sin visibilidad, no hay control.
2) Definir políticas de exposición: “mínimo necesario” por diseño
Establece reglas claras: quién accede, para qué, qué técnica aplica, qué se comparte con terceros y qué entra en IA (y bajo qué forma). Aquí es donde el Zero Trust se convierte en operación.
3) Integrar protección en el flujo: automatización consistente
El gran enemigo del ecosistema de datos de confianza cero es lo manual: es lento, inconsistente y no escala. La protección debe ocurrir antes de compartir, antes de entrenar, antes de indexar y antes de automatizar
4) Habilitar colaboración segura: equipos y proveedores sin exposición innecesaria
Confianza cero no es bloquear; es permitir que negocio, partners e innovación trabajen con datos privacy-safe sin poner en riesgo a personas ni organización.
5) Medir y mejorar: riesgo, cumplimiento y ROI
Mide reducción de exposición, tiempos ahorrados, consistencia, incidencias evitadas y velocidad de entrega. Sin métricas, no hay continuidad ni mejora.
El “riesgo invisible” que más frena a la IA: delegar autoridad sin darte cuenta
A medida que las organizaciones adoptan IA más autónoma (copilotos, agentes, automatización), surge un riesgo habitual: la toma de decisiones se desplaza gradualmente hacia sistemas automatizados si no se definen gobernanza, responsabilidades y límites. En este contexto, un ecosistema de datos de confianza cero no es solo seguridad: es gobernanza de decisiones, porque el dato protegido reduce el impacto de fallos humanos o automatizados.
Cómo se ve esto en la práctica: acelerar IA sin sacrificar privacidad
Cuando aplicas anonimización avanzada dentro de un zero-trust data ecosystem, suelen aparecer cuatro beneficios claros:
- Menos riesgo de exposición (el dato sensible no circula por defecto).
- Más velocidad (se elimina el cuello de botella manual).
- Mayor confianza (equipos y auditoría validan procesos).
- IA más útil (se conserva contexto y consistencia).
Ese es el punto: la privacidad deja de ser una barrera y se convierte en el habilitador de innovación.

Conclusión: en 2026, el perímetro ya no será tu red. Será tu dato.
NIST define confianza cero como una estrategia para proteger recursos y flujos, no ubicaciones. En la era de la IA, eso se traduce en algo muy concreto: proteger los datos dondequiera que vayan.
La adopción se está acelerando porque el impacto es tangible: hay organizaciones que han reportado ROI del 92% al 139% con Zero Trust, además de reducciones significativas en probabilidad de brecha y ataques de ransomware. El siguiente paso es aplicar esos mismos principios a la capa de datos para consolidar un ecosistema de datos de confianza cero que haga posible la IA sin asumir riesgos innecesarios.
Construir un ecosistema de datos de confianza cero con anonimización avanzada no significa “hacer más compliance”. Significa hacer posible la IA con datos gobernados, útiles y protegidos por diseño.
La innovación sostenible no depende solo de modelos. Depende de una base:
datos protegidos, útiles y gobernados.
¿Quieres implementar un zero-trust data ecosystem sin frenar tus proyectos de IA?
Solicita una demo y te mostramos cómo aplicar anonimización avanzada y seudonimización consistente en tus documentos y flujos, para proteger datos sensibles sin perder contexto ni utilidad.






