
In a landscape where privacy is as critical as innovation, organizations handling sensitive data must act now to prepare for 2026. The convergence of generative AI, new European regulations (like the AI Act), and a more privacy-aware society has raised the bar for data protection.
This article identifies the key mistakes holding back digital transformation in regulated sectors and how to fix them using real-world technologies, including automated anonymization, tokenization, and synthetic data generation with Nymiz, which delivers up to 95% accuracy in effective anonymization.
2025–2026: A perfect storm for sensitive data
A growing number of organizations are facing this dual challenge: protecting personal and corporate data while leveraging its full potential in AI initiatives. The exposure of unstructured data, lack of traceability, and manual processes continue to create serious vulnerabilities.
Preparing your sensitive data for 2026 means adopting a strategic and technological approach that combines true protection with operational utility.
The EU Cybersecurity Agency estimates that the average cost of a sensitive data breach in regulated sectors exceeds €4.45 million. Moreover, 67% of organizations in Europe lack solid protocols to anonymize data used in AI models (European Data Governance Report 2025).
The exposure of unstructured data, lack of traceability, and reliance on manual processes continue to create serious vulnerabilities. Preparing your sensitive data for 2026 means adopting a strategic and technological approach that combines true protection with operational utility.

What can go wrong? 5 critical mistakes to avoid
These aren’t hypothetical scenarios, they’re happening today in companies, public institutions, and organizations working with sensitive information without the right tools. The pressure to comply with regulations like GDPR or the AI Act, combined with the need to extract value from data in AI environments, is leading many to take hasty or insufficient measures.
Here are the most common mistakes in handling personal data in regulated sectors, with real-world examples and scalable solutions that enable protection without compromising innovation.
1. Superficial protection = False sense of security
The problem: An insurance company uses a basic script to delete names and ID numbers from its claims database. Months later, a researcher cross-references that data with public vehicle records and reidentifies over 30% of the insured individuals.
The consequence: Indirect data breach, loss of trust, and investigation by the data protection authority.
The solution: With Nymiz, anonymization goes beyond hiding visible fields. Its advanced engine allows organizations to define rules by document type and validate each output. In testing scenarios, it has reached up to 95% anonymization accuracy.
2. Over-anonymizing = Data loses its value
The problem: A hospital removes dates, locations, and clinical categories. The result: a dataset that no longer supports longitudinal analysis or predictive model training.
The consequence: Valuable insights are lost due to fear of non-compliance, halting innovation projects.
The solution: Nymiz enables synthetic data generation that replicates the structure and behavior of the original dataset without exposing personal information. Models can be trained safely and effectively.
3. Manual processes = Errors that scale with volume
The problem: A law firm manually anonymizes hundreds of contracts. In one case, a copy-paste error leaves names visible in a published document.
The consequence: Confidential information is exposed, creating legal risk and reputational damage.
The solution: Nymiz automates batch document anonymization with rule-based flows and automatic validations. This reduces human error, accelerates processes, and frees up legal teams.

4. Inconsistent anonymization = Unusable data
The problem: A company wants to merge anonymized datasets from different sources. But identifiers were transformed inconsistently, with no coherence.
The consequence: Data can’t be integrated, analysis becomes unreliable, and AI models are blocked.
The solution: Nymiz applies consistent tokenization across systems and datasets, ensuring that data retains its analytical value while remaining privacy-compliant.
5. Avoiding AI = Missed competitive advantage
The problem: A local government avoids using AI to analyze social services data due to fears of exposing citizen identities.
The consequence: Missed opportunities to automate assistance programs and predict key needs.
The solution: Nymiz generates realistic synthetic datasets that preserve critical relationships and patterns while remaining GDPR and AI Act compliant.
How to prepare your sensitive data for 2026 without slowing innovation
This model ensures your datasets retain analytical value while minimizing risk. Tools like Nymiz simplify this pipeline through automation and precision anonymization.
Privacy shouldn’t block AI or digital transformation. With the right tools, organizations can stay compliant, protect individuals, and unlock real value.
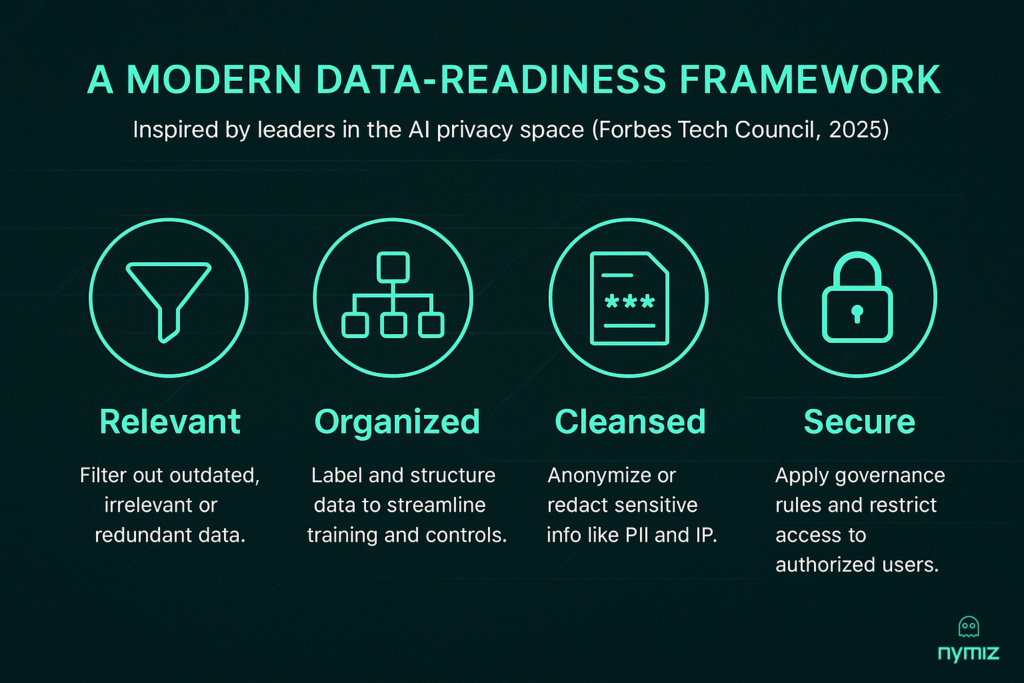
Technologies to use
- Tokenization: To maintain consistency across systems.
- Synthetic data: To train AI without exposing real data.
- Batch processing: To scale without manual errors.
- Automated anonymization: For faster, more accurate, and traceable results.
Practices to avoid by sector
- Healthcare: Removing temporal or key clinical sequences.
- Finance: Breaking relationships that affect scoring or fraud analysis.
- Legal: Anonymizing without preserving legal context.
- Public sector: Publishing data without version control or risk evaluation.
How to measure success
- Anonymization accuracy (Nymiz achieves up to 95%).
- Average time per batch processed.
- Auditable compliance levels.
- Post-anonymization data utility.
Sector use cases: From problem to solution
See how different sectors are already preparing their sensitive data for 2026 using real-world solutions:
Healthcare
Challenge: Share clinical data without violating GDPR.
Solution: Synthetic data based on real datasets, preserving clinical patterns.
Impact: AI trained with no legal risk.
Finance
Challenge: Share data with fintechs without exposing identity.
Solution: Tokenization + pseudonymization.
Impact: Scoring models fully compliant.
Legal
Challenge: Train a legal model with thousands of confidential documents.
Solution: Batch anonymization with document-specific rules.
Impact: Functional AI with no privacy exposure.
HR
Challenge: Analyze talent attrition without revealing identities.
Solution: Pseudonymization + attribute anonymization.
Impact: Aggregated insights with zero exposure.
Public Sector
Challenge: Publish open datasets without breaching privacy.
Solution: Synthetic data generated from versioned anonymized sources.
Impact: Transparency with citizen data protected.
FAQ
– What’s the difference between anonymization and pseudonymization?
Anonymization eliminates all possibilities of identifying a person. Pseudonymization replaces identifiers with reversible keys. Synthetic data is artificially generated and contains no real personal information.
– Can I train AI using anonymized data?
Yes, as long as correlations are preserved and data utility is maintained. With Nymiz, anonymization retains structure and coherence.
– What’s the difference between tokenization and synthetic data?
While both protect sensitive information, their approaches differ. Tokenization replaces identifiable elements with unique tokens, preserving relationships without revealing original values—ideal for maintaining consistency across systems. Synthetic data, on the other hand, is generated based on real patterns, but contains no actual personal data. It’s ideal for training AI models, sharing with third parties, or simulations with zero risk
– How does Nymiz ensure GDPR and AI Act compliance?
Nymiz supports risk-based anonymization, tokenization, and synthetic data generation—all recognized by authorities like AEPD and ENISA. It also allows for rule configuration by data type and sector, ensuring full traceability and audit documentation.
– Can I maintain relationships between records after anonymizing?
Yes. With Nymiz’s consistent tokenization, links between records across databases are preserved without exposing identities—supporting analysis and modeling.
– What kind of data can Nymiz anonymize?
Nymiz supports both structured data (databases, tables) and unstructured data (legal docs, PDFs, clinical texts), adapting its strategies based on content type and intended use.
– Can Nymiz integrate with my existing systems?
Yes. Nymiz offers API-based integration and batch processing, working with both on-premise and cloud architectures.
Ready to turn privacy into competitive advantage?
Organizations that anticipate privacy challenges today will be the ones leading innovation tomorrow. Preparing your sensitive data for 2026 isn’t just a compliance requirement: it’s a strategic move.
With Nymiz, you can turn your data pipeline into a secure, automated, and value-generating asset. You no longer have to choose between compliance and efficiency, you can have both.
Request a free demo with our experts and discover how anonymization with up to 95% accuracy can power your AI projects, safely and reliably.

Recommended resources & references
- Data breach costs and compliance risks: IBM – Cost of a Data Breach Report 2025
- Data governance and privacy in AI (OECD framework): OECD – AI, Data Governance and Privacy
- Trends and obstacles in AI for 2025: Ditrendia – AI report 2025
- Effective anonymization in AI environments: Forbes – Anonymizing Data for AI Success
- Academic research on privacy in AI: ScienceDirect – AI and Data Privacy
- Global privacy & AI usage statistics: Protecto.ai – AI Privacy Trends 2025
- Cisco 2025 Data Privacy Benchmark Study – Cisco newsroom release






