
The problem isn’t the volume of documents—it’s how they’re managed
Public institutions handle an extraordinary number of documents daily: court rulings, administrative records, medical histories, social files, public contracts, and citizen requests. This document flow, essential for the functioning of the state, contains — in the vast majority of cases — sensitive personal data. The challenge is not recognizing their existence, but rather acknowledging that the way this information is handled hasn’t evolved at the same pace as its volume or the current regulatory pressure.
In a context of accelerated digitalization, administrative interoperability, and increasing demand for transparency, data anonymization is no longer a reactive or one-off task. It’s a critical function within any privacy protection strategy in public settings. However, the central issue is not what needs to be protected, but how: in many institutions, anonymization is still carried out manually, with outdated or fragmented tools. In the public sector, this isn’t just inefficient — it’s a legal and operational liability.
What public sector documents actually contain—and why they must be protected
Understanding the gravity of this issue requires a closer look at the types of data these public documents contain. It’s not just names or addresses. These records reflect full administrative, legal, medical, and social trajectories. A single file might contain a national ID number, full address, handwritten signature, diagnosis, family situation, a QR code, and an image scan with marginal notes.
We can group this information into five major data categories that require protection:
- Direct personal data: full names, postal addresses, phone numbers, email addresses, national IDs, vehicle plates, or case numbers.
- Special categories of personal data: health conditions, diagnoses, treatments, disability certifications, union affiliation, religious beliefs, or political ideology.
- Technical identifiers: digital signatures, barcodes, QR codes, official seals, document hashes, or metadata fields that may not appear sensitive but are uniquely identifiable.
- Visual and contextual elements: scanned images, screenshots, or diagrams containing embedded personal information often missed by conventional tools.
- Inferential or combined data: combinations of age, job title, region, and date that, together, allow re-identification even when direct identifiers have been removed.
Protecting this data means more than redacting names. It requires a system capable of identifying direct and indirect identifiers, understanding document context, and applying irreversible data anonymization without damaging the document’s integrity. Manual workflows can’t achieve this standard — and when they fail, people’s data is left exposed.
Manual anonymization can’t match today’s speed or risk levels
In most public institutions, data anonymization is still done manually. Not because it’s ideal, but because it’s how it’s always been done. Technicians review files line-by-line, identify sensitive fields, and obscure them using basic PDF tools or word processors. This model doesn’t scale. And more importantly: it’s been kept alive despite growing volumes, stricter regulations, and more severe consequences of failure.
- It’s slow: reviewing even small batches takes hours or days. Deadlines are missed, teams are overwhelmed, and transparency suffers.

- It’s fragile: human attention spans vary. In repetitive workflows under pressure, omissions and inconsistencies are inevitable.
- It’s inconsistent: different reviewers apply different criteria. Some over-redact, others under-redact. Structural coherence is lost, and traceability becomes impossible.
Under pressure — whether from regulatory timelines, citizen requests, or media attention — improvisation becomes the norm. And every improvised process is a risk waiting to materialize.
What the law demands: from theory to enforcement
Data anonymization is not optional. It’s a legal requirement in the EU and beyond. The General Data Protection Regulation (GDPR) establishes that all personal data processing must be secure, proportionate, and transparent. Article 25 mandates data protection by design and by default. This means anonymization must be part of the system architecture — not an afterthought.
Other regulations support this requirement:
- In Spain, the LOPDGDD reinforces GDPR with emphasis on public data controllers.
- In the U.S., laws like HIPAA (health data) and FOIA (freedom of information) require redaction or anonymization before disclosure.
- Brazil’s LGPD demands irreversible anonymization to exclude data from privacy rules.
- China’s PIPL prohibits identification via direct or indirect means unless strictly authorized.
- The Council of Europe’s Convention 108+ obliges signatories to implement anonymization techniques as safeguards.
All these frameworks converge on one point: you must prove that your data anonymization works—and that it can’t be reversed.
The power of AI in public sector data privacy
Artificial intelligence is not a generic solution or a fad applied indiscriminately to the public sector. In the context of data anonymization, its role is structural. It allows us to move from a manual, limited, and fragmented approach to an automated, replicable, and auditable one. The key is not whether AI “does the work,” but how it transforms the process: it moves from relying on the human eye to relying on systematic detection, logical configurations, and semantic validation.
In mass anonymization processes, AI performs four critical functions:
- Multi-channel detection of sensitive data: It can identify names, addresses, ID numbers, QR codes, handwritten signatures, and other infotypes in plain text, images, scanned fields, or documents with disordered structures.
- Contextual understanding: Unlike keyword-based approaches, systems based on natural language models can distinguish when a name is an identifiable entity and when it is not, applying context-specific rules.
- Application of risk-based data anonymization techniques: Not all data should be treated equally. AI can apply generalization, suppression, pseudonymization, or redaction depending on the data type, regulatory environment, or project configuration.
- Scalability without loss of quality: While humans tire, automated models maintain consistent levels of accuracy, even in batches of thousands of documents, with the possibility of subsequent manual review in borderline cases.
Rather than replacing equipment, AI frees up its operational burden, reduces human error, and transforms anonymization into a sustainable practice. This isn’t generic automation. It’s expertise applied to public privacy, in an environment where compliance can no longer depend on personal effort but on intelligent systems design.
Automate data anonymization with batch processing
One of the major challenges facing the public sector is the practical impossibility of anonymizing documents on a per-document basis in real-world administrative workflows. Existing solutions either focus on specific formats or offer isolated functionalities without orchestration capabilities.
This is where Nymiz Batch Processing comes in, designed to deliver massive, accurate, and legally compliant data anonymization without sacrificing context or structure.
Here’s the step-by-step process:
- Centralized document upload: Hundreds or thousands of files can be uploaded at once, in different formats such as PDF, Word, scans, or images in batches. There’s no need to standardize them beforehand. AI adapts them.
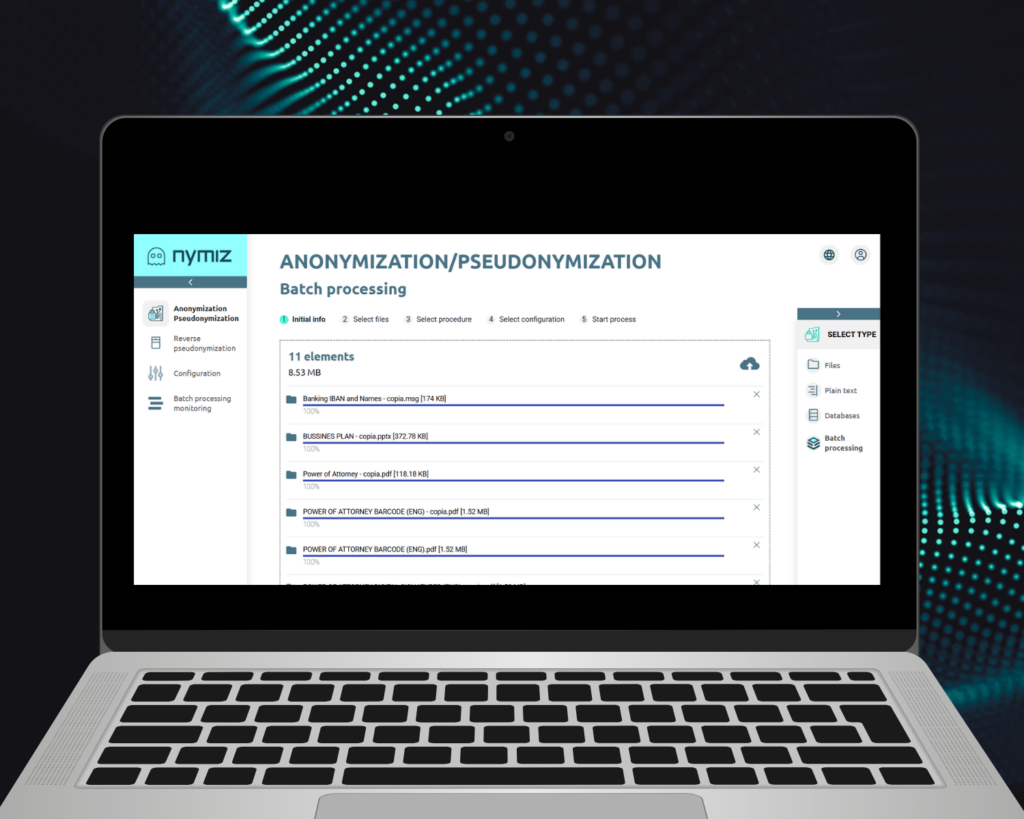
- Specific configuration selection: The user chooses an anonymization profile appropriate to the use case: justice, healthcare, education, access to public information, etc. Each includes customized rules for which types of data should be protected and how.
- Semantic analysis and automatic detection: The system recognizes infotypes in any position, orientation, or structure, and applies the corresponding technique based on the data and its contextual environment.
- Irreversible application of anonymization: Each detected data item is transformed through non-reversible deletion, redaction, or substitution. The resulting document retains its structure, non-sensitive fields, and informational value.
- Traceable monitoring and export: It can be reviewed batch by batch or document by document, with logs, rules applied, and performance metrics. Everything is recorded for internal or external audits.
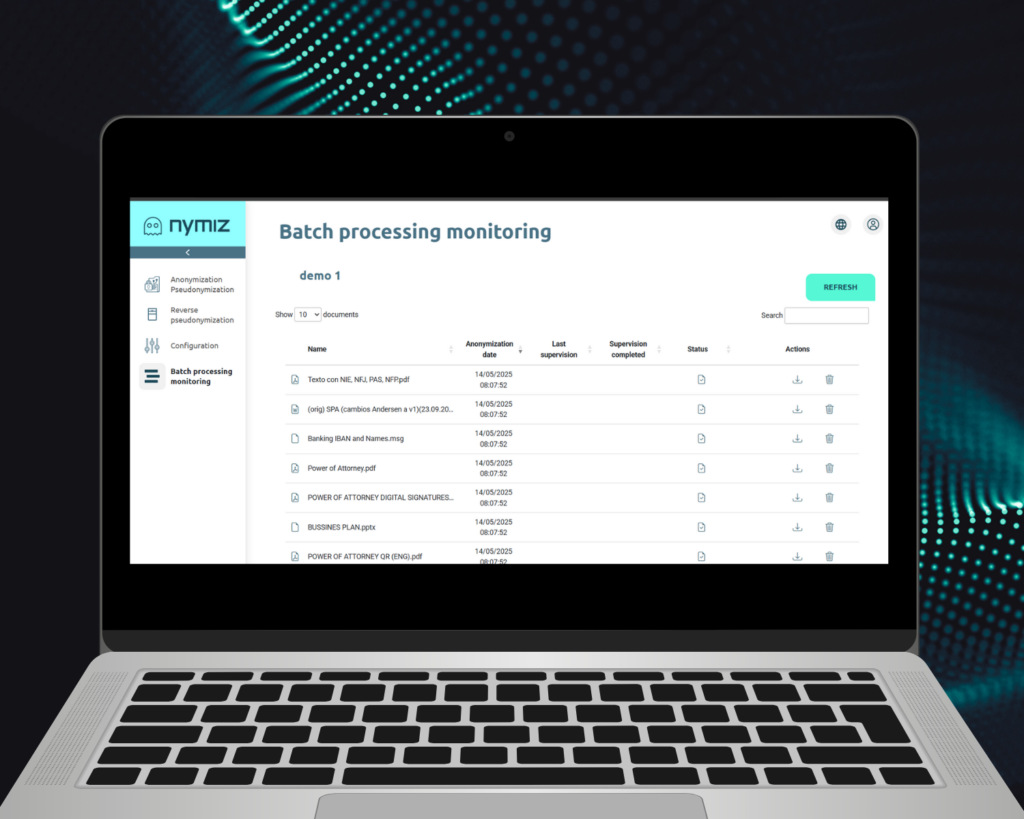
The result is a system that can anonymize in seconds what previously took hours, without sacrificing accuracy or compliance. This feature makes anonymization an integrated layer of the document workflow, rather than an operational hindrance.
Why choose Nymiz as your anonymization tool?
The choice of a technological solution shouldn’t be based on trends or brands. It should answer a specific question: does this tool solve my problem in the legal, technical, and operational context in which I work? Nymiz was created to answer that question affirmatively in the public administration environment, with a specific focus: automated, accurate, and auditable data anonymization.
Unlike other generic tools or those designed for corporate environments, Nymiz offers:
- Specialization in unstructured data: Many public sector documents don’t follow a fixed template. Nymiz is designed to work with rotated or scanned text, with overlapping fields, or chaotic structures.
- Interface designed for technical and non-technical teams: no prior programming knowledge is required. It is configured on a project-based basis, with reusable profiles and monitoring workflows designed to comply with internal rules and external regulations.
- Batch processing as a core, not an add-on: While other solutions allow multiple files to be uploaded but process them one by one, Nymiz has been designed for batch processing from the ground up. It not only allows automation, but also does so meaningfully, according to rules, and with control.
- Demonstrable compliance: Each process generates full traceability. The rules applied, the data detected, the methods used, and manual decisions are documented to facilitate audits or regulatory defenses.
Choosing Nymiz isn’t just a technical decision. It’s a commitment to a system designed with institutional privacy in mind. Not to barely comply, but to comply with structure, scalability, and meaning.
Data anonymization can no longer depend on individual effort
The public sector can no longer afford to rely on the will, attention, or availability of its teams to fulfill its privacy obligations. Volume prevents it. Complexity overwhelms it. And the law no longer allows for improvised processes. In this scenario, data anonymization ceases to be a technical practice and becomes a structural function.
Automating this process doesn’t mean losing control, but rather gaining it. It means establishing rules, complying with standards, freeing up resources, and responding to a requirement that is no longer just legal, but ethical: protecting citizens’ identities, even in seemingly minor details.
Nymiz proposes a concrete way to make this possible. Not with promises, but with features designed for real documents, complex contexts, and demanding regulations.
In the new balance between transparency and privacy, data anonymization is not an obstacle. It is the key to enabling the government to operate responsibly.
Request a personalized demo and discover how we do it at Nymiz.






