
The Zero Trust conversation often starts (and sometimes ends) with identities, networks, and access control: “Never trust, always verify.” It’s a major step forward, and NIST is clear about it: Zero Trust is about securing resources and workflows, not traditional perimeters.
But in 2025–2026, a quieter shift is happening: the new perimeter is the data. Data now moves faster and farther than ever: across teams, vendors, clouds, and especially into automation workflows and AI systems. That creates a common challenge in AI adoption: you can have excellent access controls and still expose sensitive information at the moment it’s used.
Zero Trust is no longer a “trend”, it’s becoming foundational. In fact, 73% of organizations are actively implementing or planning Zero Trust strategies, primarily driven by the need to protect data, prevent breaches, and reduce insider threats.
So the question is no longer, “Do we have Zero Trust?”
The real question is: Do our data live inside a zero-trust data ecosystem?
Zero Trust is no longer just about networks and identities: The new perimeter is your data
In hybrid environments, where internal and external collaboration is the norm and AI is increasingly embedded in critical processes, data has become the most mobile asset… and often the most exposed. Innovation today doesn’t depend only on granting access, but on continuous data reuse: analytics, automation, reporting, audits, and model training/evaluation.
That’s why many organizations feel secure “in theory” but vulnerable “in practice”: security efforts concentrate on perimeter and access, while real risk emerges once data leaves its original context and starts circulating.
The limit of “traditional” Zero Trust: Protected at rest and in transit… exposed in use
Encryption, segmentation, and access control protect data at rest and in transit. But once a user (or system) legitimately accesses a document or dataset, that content can:
- be duplicated across tools,
- be shared with third parties,
- enter AI pipelines,
- or be exposed through operational mistakes, especially when data is reused across multiple systems and workflows.
In other words: perimeter and access security are necessary, but not sufficient. If your organization is deploying AI, you need an operational principle: never trust unprotected data, even inside your own environment.
What a Zero-Trust data ecosystem means
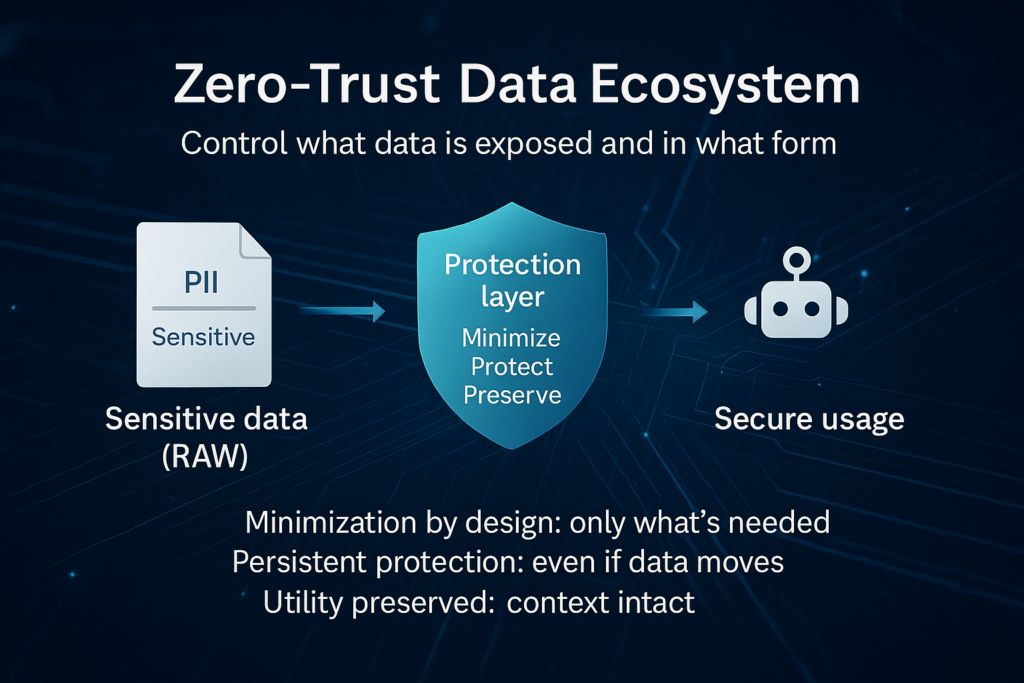
A zero-trust data ecosystem is an operating model where sensitive data does not move “as-is” by default. Instead of relying only on who has access, it focuses on what data is exposed and in what form—applying systematic protection so risk is reduced even when data moves.
In practice, this requires three shifts:
- Privacy minimization by design: share only what is necessary.
2. Persistent protection: data remains protected even as it moves across systems, teams, or vendors.
3. Preserved utility: data stays useful for AI, analytics, and operations, without breaking context.
This aligns with the evolution of Zero Trust itself: organizations don’t just want to “control access,” they want to reduce breach likelihood, operational impact, and insider risk. Extending Zero Trust principles to the data layer, not just access, is the natural next step toward a zero-trust data ecosystem.
Why advanced anonymization is an accelerator
A common misconception is that protecting data always reduces its value. That’s true when protection is manual, inconsistent, or overly aggressive. Advanced anonymization changes the equation by pursuing a difficult but essential balance: reduce identifiability without destroying context.
In a zero-trust data ecosystem, advanced anonymization accelerates AI adoption for three reasons:
- It reduces exposure systematically (not as a one-off).
- It scales collaboration and AI usage without manual friction.
- It preserves data utility for automation, research, audits, and models.
Most importantly, Zero Trust doesn’t only reduce risk—it can deliver measurable returns. Microsoft reported a 92% ROI over three years, with payback in under six months, and a 50% reduction in breach likelihood after adopting Zero Trust disciplines. Similarly, Zscaler reported $4.1M in savings, 139% ROI, and 85% fewer successful ransomware attacks with its Zero Trust Exchange model.
If those outcomes appear when strengthening controls and Zero Trust discipline, the next logical step is to protect the most critical asset: the data itself. That’s where advanced anonymization helps scale AI within a zero-trust data ecosystem, reducing exposure without compromising utility.
How Nymiz helps build a Zero-Trust data ecosystem with advanced anonymization
At Nymiz, we design our technology so data protection isn’t a manual step “at the end,” but an embedded layer within operational workflows. That approach is key to a zero-trust data ecosystem: sensitive data is transformed in a consistent, governed, and scalable way before it moves across the organization or enters AI processes.
What does that enable in practice?
- Advanced anonymization for unstructured documents (PDFs, contracts, case files, exported emails, presentations), preserving layout and readability so content remains usable.
- Consistent pseudonymization to maintain controlled traceability when the use case requires it (audits, analytics, legal workflows).
- Project-level configurations (rules, exceptions, and info types) to align protection with internal policies and regulatory requirements—avoiding one-size-fits-all approaches.
- Batch processing to apply the same rules at scale, reducing operational risk and dependence on manual work.
- Review and validation when an additional quality control layer is needed.
The outcome is tangible: teams can anonymize in seconds, achieve 95%+ accuracy on complex texts, and save up to 80% of the time compared to manual or traditional method, without sacrificing data value or breaking the context AI needs to perform.
In 2026, the advantage won’t be “using AI.” It will be using AI with privacy as infrastructure: fast, consistent, and built to scale inside a zero-trust data ecosystem.
Key techniques: Not everything should be protected the same way (And that’s a good thing)
A zero-trust data ecosystem isn’t built on a single technique. It requires a governed approach that selects methods based on the use case, risk level, and traceability needs.
Pseudonymization: Privacy with controlled traceability
Best when you need consistency (same entity, same pseudonym) to preserve coherence across legal processes, audits, analytics, or automation.
Masking and Generalization: Practical minimization
Useful when only ranges or categories are needed (e.g., approximate age, region, segment), reducing exposure without losing operational utility.
Synthetic data (and robust approaches): When risk is high and usage is intensive
When you need to train, evaluate, or test models without using real data, synthetic data can enable innovation with lower exposur, provided quality controls and risk assessments are in place.
Differential privacy: Statistical protection for aggregation scenarios
Appropriate for analytics where you want to limit re-identification from repeated queries over aggregated datasets.
A practical framework: 5 steps to build your Zero-Trust data ecosystem
If you want to build a zero-trust data ecosystem in a realistic way (especially in the public sector, banking, legal, or healthcare), this framework works because it combines data discovery, automation, and governance.
1) Identify and classify: A real inventory (Including unstructured data)
Map what documents/datasets you handle, where they live, what they contain (PII, sensitive data), and which workflows consume them (including AI). Without visibility, there’s no control.
2) Define exposure policies: “Minimum necessary” by design
Set clear rules: who accesses what, for what purpose, which technique applies, what’s shared with third parties, and what enters AI (and in what form). This is where Zero Trust becomes operational.
3) Embed protection in the workflow: Consistent automation
The biggest enemy of a zero-trust data ecosystem is manual work: it’s slow, inconsistent, and doesn’t scale. Protection should happen before sharing, before training, before indexing, and before automating.
4) Enable safe collaboration: Teams and vendors without unnecessary exposure
Zero Trust isn’t about blocking: it’s about enabling business, partners, and innovation to work with privacy-safe data without putting people or the organization at risk.
5) Measure and improve: Risk, compliance, and ROI
Track exposure reduction, time saved, consistency, incidents avoided, and delivery velocity. Without measurement, there’s no sustainability, and no improvement.

The “invisible risk” that slows AI down: Delegating authority without noticing
As organizations adopt more autonomous AI (copilots, agents, automation), a frequent risk emerges: decision-making gradually shifts toward automated systems unless governance, accountability, and boundaries are clearly defined. In this context, a zero-trust data ecosystem is not only about security: it’s decision governance, because protected data reduces the impact of both human and automated failure modes.
What it looks like in practice: Accelerating AI without sacrificing privacy
When you apply advanced anonymization inside a zero-trust data ecosystem, four outcomes typically follow:
- Lower exposure risk (sensitive data doesn’t circulate by default).
- Higher speed (manual bottlenecks disappear).
- Greater trust (security and audit teams can validate the process).
- More useful AI (context and consistency are preserved).
That’s the point: privacy stops being a barrier and becomes the enabler of innovation.

Conclusion: In 2026, the perimeter won’t be your network. It will be your data.
NIST defines Zero Trust as a strategy to protect resources and workflows—not locations. In the AI era, that translates into something very concrete: protect data wherever it goes.
Adoption is accelerating because the impact is tangible: organizations have reported 92% to 139% ROI with Zero Trust, along with meaningful reductions in breach likelihood and ransomware success rates. The next step is applying the same principles to the data layer—building a zero-trust data ecosystem that makes AI possible without taking unnecessary risk.
Building a zero-trust data ecosystem with advanced anonymization doesn’t mean “doing more compliance.” It means enabling AI with data that is governed, usable, and protected by design.
Sustainable innovation doesn’t depend only on models. It depends on a foundation:
protected, usable, and governed data.
Want to implement a zero-trust data ecosystem without slowing down your AI initiatives? Request a demo and we’ll show you how to apply advanced anonymization and consistent pseudonymization across your documents and workflow, protecting sensitive data without losing context or utility.






